
数据库故障是不可避免的,任何软件,无论是开源类还是商业类,只要是人创造的,就一定会存在产品缺陷(bug),软件越复杂,承载任务越繁多,触发bug的概率就越大,这是IT人的基本常识。
快速定位能力的关键性
真正重要的是,在出现故障时,如何迅速而有效地应对故障,定位故障根因并给出有效的解决方案,这才是确保业务连续性和稳定性的关键。也是决定一款数据库是否成熟的一项关键指标。
可是,也不知道当下风气是怎么了,好多人吧,不踏下心来好好研究自家产品,反而喜好打听别家谁出了啥故障,打听到后就跟中了彩票一样兴奋,之后就开始大作文章,跟客户直接说这产品不行。不晓得这些人是纯粹的天真,不知道这个道理,还只是为了各自利益,揣着明白装糊涂呢?
聊到数据库的故障,这里先抛开其他除数据库本身之外进而引发数据库故障的复杂情况不说,也暂不去讨论因用户操作使用不当这类导致的故障,就只是单纯的聊下所谓很严重的产品本身bug导致的故障。
为了客观,避免有些人又喜欢去对号入座,我们就以业界公认领先的,各方面指标均很优秀的商业数据库产品Oracle来举例,因为它本身承载着当今世界众多重要客户的核心系统,这些人总不能去喷Oracle这款数据库产品也不行吧。
Oracle产品本身bug多么?
Oracle产品本身bug多么?
其实真的很多。
但凡你有在生产环境部署过Oracle数据库,应用过PSU/RU补丁集,就会发现光是建议应用的这些补丁集列表中的bug就非常多,opatch lsinventory 列出的bug号码都能铺满好几页屏幕。
可是,因这些产品bug导致的故障多么?
如果单拎出来某一个客户来讲,其实是不多的,甚至还存在许多自使用以来从未遇到任何软件bug导致故障的幸运客户,尤其一些IT建设比较薄弱的客户,虽然购买了Oracle,但也没打啥补丁,甚至一直连MOS都没登录过,压根儿就没遇到任何产品bug引发的问题。
但是每个bug其实都直接或间接的对应了某个场景下的故障,那这么多隐秘的bug在测试时都没发现,最终又都是咋发现的呢?
反而是因为Oracle太流行,用户太多太广了,开头也提到了,bug这东西本身触发概率并不高,再举个量化的例子,比如说某个bug只有万分之一的概率被用户触发,也就是说1万个用户里面估计也只有一个人能有幸遇到,于是他遇到过提交给官方,出补丁,其他客户定期更新补丁集,就不会再遇到这个bug。
另外,如此庞大复杂的软件其实bug有很多的,但因为你这个场景遇到了A bug,我这个场景遇到了B bug,他那个场景遇到了C bug… 不断完善,你要是想成为全球第一个遇到某个bug的用户,其实都不太容易呢,所以产品稳定性得到了保障。
如果你的IT管理很有章程,按照官方的建议,定期更新推荐的补丁集,实际上就很难遇到bug带来的影响;即使有的客户因各种原因没有及时应用推荐的补丁集,某一天好巧不巧的触发了某个bug,基本MOS一查现象,也大概率会是已知bug,别人早就遇到了,补丁都是现成的,你只需要及时应用这个补丁即可解决。
小概率事件就可以忽略吗?
既然这样,那用户真的就可以无为而治,万无一失了吗?
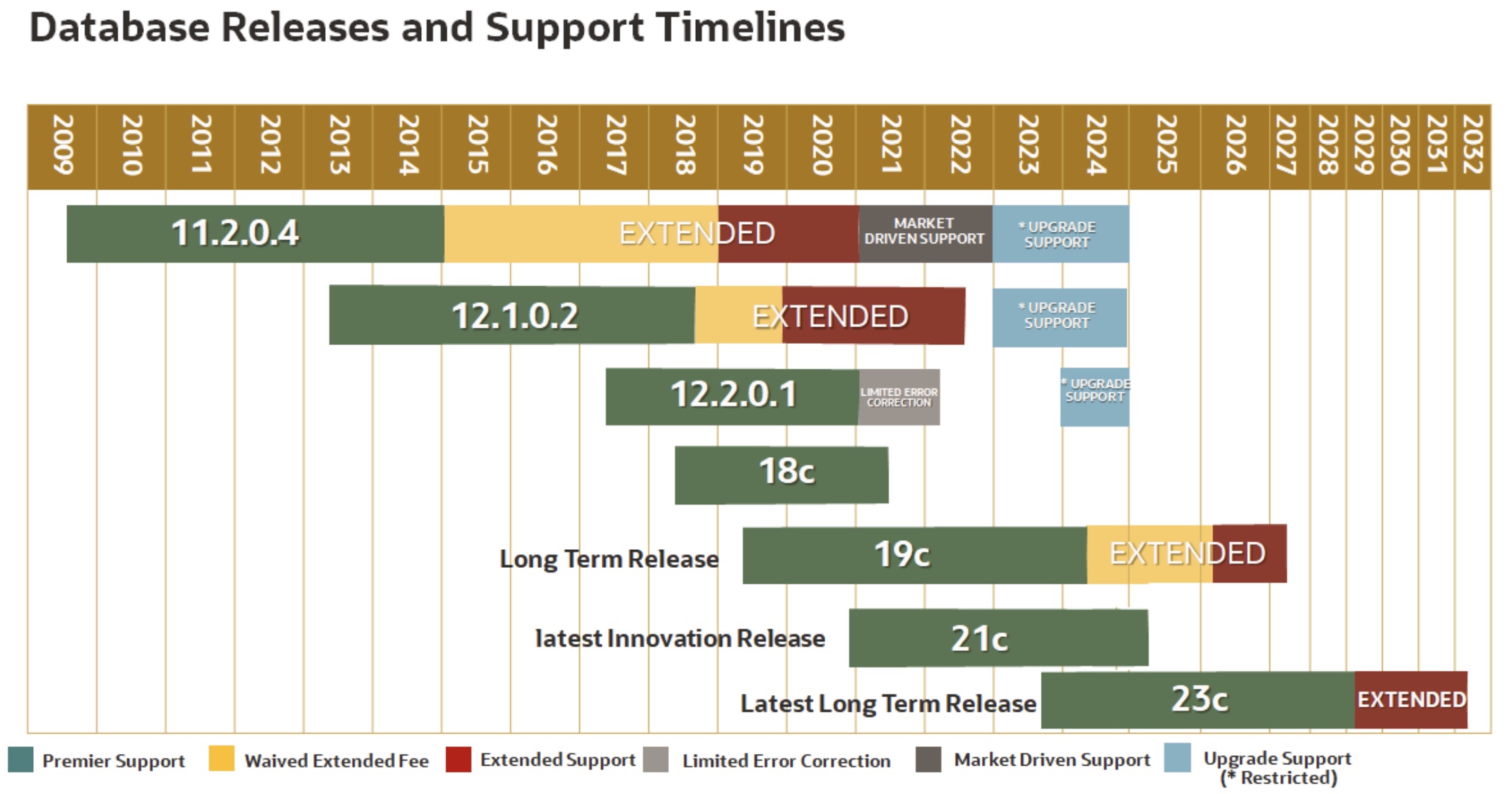
也不是,小概率事件不等价于不可能发生事件,为了万无一失,还是要确保你所使用的版本在支持周期之内。这也是为什么有的用户讲我不用你新版本的new feature,为啥也要跟着升级版本的原因之一。
很多人会抱着侥幸心理觉得无所谓,自己不会那么倒霉,但一旦真的不幸遇到就会痛苦不堪。
这里再举个实际的例子吧,比如最近就遇到了一个case,简单说的确是因为产品本身bug导致的故障,现象是ADG的Redo Apply缓慢,这个bug其实也非常隐蔽,因为正常平时延迟都是0,根本发现不了,可运气不好的是,恰好在某个重要保障节点,因为OOM类的原因导致ADG同步被意外终止,且也没有被及时监控到,等用户感知到时,已经有了数小时的延迟,正常情况下,这问题也不大,重新启动同步进程Redo Apply也是很快会追平,可此时不幸的发现追日志的效率异常缓慢,基本相当于延迟多久就追了多久,虽然MOS能查到这个问题,也是一个已知的bug,但更不幸的是,目前在MOS上针对这个bug只有Linux平台的现成补丁,而客户的系统是AIX,并没有找到对应补丁,同时与后台SR进一步确认,确认是真没有,且研发也不会再出这个补丁了。
为什么呢?
因为这是一个老的数据库版本,已经不在支持周期内,研发不会为此提供新的补丁。
好在这个bug不算硬伤,追上这次意外的gap之后就可以保持同步,可风险其实依然存在,在升级之前,我们也只能加强监控,避免类似问题发生影响,并强烈建议尽快把版本升级提上日程。
可能有人会讲,一个已知bug,别的平台都出了补丁,为啥就不能也给出个其它平台的补丁呢?要知道打个one-off的patch是很轻松的事情,但大版本升级可是一个大动作,还要协调应用测试配合,干嘛搞这么复杂呢?
其实这样的策略才是真正的对客户负责,也是很合理的,首先Oracle一直都建议用户要使用当前有效期内的LTS长期支持的版本,这样才能集中更多人来更好的保证你的稳定性,Oracle的LTS其实已经是支持周期非常久的了。
而且,不升级的话,就算研发帮你修复了这个bug,但是后续的风险其实会更大,这种已不在支持周期内的版本,万一下次遇到的bug是非常严重的呢?
数据库有故障怎么了?
最后,回到正题,数据库有故障怎么了?
还是那句话,数据库是一个软件,而且是一款非常复杂的软件,遇到故障是再正常不过的,如何迅速而有效地应对故障,定位故障根因并给出有效的解决方案,这才是确保业务连续性和稳定性的关键。
如果说谁家的数据库产品至今为止,都没有任何产品bug导致的故障案例,那并不代表这个数据库产品有多稳定,反而大概率是这个产品的用户量不够,没有积累到足够量的用户去踩到坑而已。
与其纠结这个无意义的话题,不如多多修炼内功,做些真正的实事。
如果是用户角度,首先要了解如何正确的使用自己选择的这款产品,最起码要能避免一些低级错误引发的故障;要知道即便是Oracle的用户群中也存在这样一波人,就是喜欢不读文档不看MOS,凭着自己的感觉不按官方建议的各种瞎搞,结果在一次次变更中因为理解错误、考虑不周导致故障频发,彷佛用的是一款山寨产品一样,最后埋怨产品不稳定,花大价钱找专家兜底排查,结果发现根因全都是胡搞导致的。
如果是厂商角度,不要怕故障,而是会在每次故障后做好支持服务,积累经验,其实可以参考Oracle的做法,建立类似MOS一样的知识库,提供完善且有实际意义的官方文档,至少确保自己的用户群中,有心学习的人是可以依据官方文档的内容,正确的使用产品、排查常规问题。即便是遇到一些疑难的,诸如产品的bug引发的故障,那也不是黑料,而是不断帮助厂商完善产品的弹药。
当然,现实真正要做到这些都不是容易的事情,但DB这个赛道本就不是容易的。如果没想好,还不如先多多去学习别人先进的经验,而不是自己的产品都没几个用户使用,却忙着去挖别人的“黑料”恶意竞争。
